

Das »Deep Web« und was wir gewöhnlich davon sehen
••• Das Web ist größer, als die meisten von uns denken. Milliarden von Websites werden von den Robotern der Suchmaschinisten eingesammelt und katalogisiert. Aber Google, Bing, Yahoo und Co. fischen nur die Oberfläche des Netzes ab. Etwa 500 mal mehr Websites existieren in den Tiefen, dem so genannten »Deep Web«. Dass wir nichts von ihnen wissen, liegt an den Siegelbewahrern des Netzes (kommerziellen Firmen und Konsortien) und natürlich den Betreibern dieser Sites. Sie wollen gar nicht von jedem gefunden werden. Den einen ist das »Deep Web« die letzte Bastion der entschwindenden Netzfreiheit, den anderen ein Abyss der Cyber-Kriminalität — eine Parallelwelt, in der es alles gibt, was man sich vorstellen und auch nicht vorstellen kann, wohlfeil angeboten gegen eine weltumspannende Währung, die international anonyme Zahlungen im Handumdrehen ermöglicht. Das wollte ich mir mal genauer ansehen.
Namen und Adressen
Um mit dem Webbrower eine Website ansehen zu können, braucht der Computer mehrere Schlüsselinformationen:
- die IP-Adresse
- den Port
- das zu verwendende Protokoll und in den meisten Fällen
- den Namen der Site.
In aller Regel braucht man jedoch nur den Site-Namen zu wissen. Die übrigen Informationen beschafft sich der Browser über Internet-Dienste, bzw. sie ergeben sich aus Internet-Standards. So laufen die meisten Web-Dienste auf denen für das jeweilige Protokoll vorgesehenen Standard-Ports: 80 für HTTP (unverschlüsselt) und 443 für HTTPS (verschlüsseltes HTTP).
Für die Auflösung von Namen in IP-Adressen (plus ggf. einen vom Standard abweichenden Port) ist der Domain Name Service (DNS) zuständig. Er liefert zu einem Hostnamen die jeweilige IP-Adresse zurück. Der Browser verbindet sich immer zu einer solchen Adresse und übermittelt lediglich auf der Protokoll-Ebene den Namen des gewünschten Hosts. Der Server entscheidet dann in aller Regel auf Basis des Namens, welche Inhalte er liefert. So können auf einem einzelnen System mit nur einer IP-Adresse sehr viele virtuelle Hosts betrieben werden. Fragt man den DNS aber nach dem Namen für eine bestimmte IP-Adresse, wird nur der Hauptname des Hosts zurückgeliefert, nicht jedoch alle möglichen Namen, für die unter der Adresse Inhalte bereitgehalten werden.
Alternative DNS-Dienste
Über die offizielle DNS-Infrastruktur wacht die ICANN (Internet Corporation for Assigned Names and Numbers) mit ihren jeweiligen nationalen Sub-Unternehmen, in Deutschland bspw. der DENIC. Diese Konsortien entscheiden darüber, welche Arten von Namen für Hosts verwendet werden dürfen und wie, durch wen und wo die Hostnamen in der hierarchischen Struktur der DNS-Dienste gelistet werden. Umsonst und gänzlich anonym bekommt man einen solchen Domain-Namen nicht. Die bekannten Suchmaschinen kümmern sich auch nur um die in diesem Netzwerk verwalteten Top-Level-Domains (com, net, org, edu, gov, de und wie sie alle heißen).
Mit einer alternativen DNS-Hierarchie, in der auch andere Hostnamen verwendet werden können, ist man bereits im »Web-Untergrund«, ohne damit gleich »illegal« sein zu müssen. Ein Beispiel für einen solchen alternativen DNS-Service ist das OpenNIC Project. In diesem sind Top-Level-Domains wie bbs, dyn, free, fur, geek, gopher, indy, ing, micro, neo, null, oss, parody und pirate vertreten. Will man solche Websites besuchen, muss man dafür sorgen, dass der Webbrowser diese Namen zu Adressen auflösen kann. Also muss man einen der OpenNIC-DNS als Nameserver verwenden. Diese werden von Freiwilligen betrieben und nutzen die gleiche Server-Software wie die DNS des »offiziellen« Web, dessen Namen sie demnach auch zusätzlich zu den OpenNIC-Namen auflösen können.
Da sich die großen Suchmaschinen um diese Sites nicht kümmern, ist man, um Websites im OpenNIC-Web zu finden, auf spezielle Suchdienste angewiesen wie etwa grep.geek.
Hinter dem Tor
Einen deutlichen Schritt weiter (und damit tiefer ins »Deep Web« geht man mit »Tor«. Dabei handelt es sich um eine alternative Netzstruktur, die auf den Strukturen des Internet aufbaut, jedoch Anonymität und eingeschränkte Rückverfolgbarkeit hinzufügt.
Sehr verständlich beschrieben wird die Funktionsweise auf TheHackerNews von Mohit Kumar, dessen Grafiken ich an dieser Stelle lediglich auf Deutsch erklären möchte.
Stellen wir uns ein typisches Szenario vor: Alice (bspw. ein Web-Surfer) möchte sich anonym über das Tor-Netzwerk mit Jane (einer Deep-Web-Site) verbinden. Verwendet wird dafür ein gewöhnlicher Webbrowser und die Zusatzsoftware Tor. Sie sorgt dafür, dass die Verbindung zwischen Alice und Jane nicht auf direktem (und damit nicht anonymem und rückverfolgbarem) Weg hergestellt wird, sondern über mehrere andere Rechner des Tor-Netzwerks.
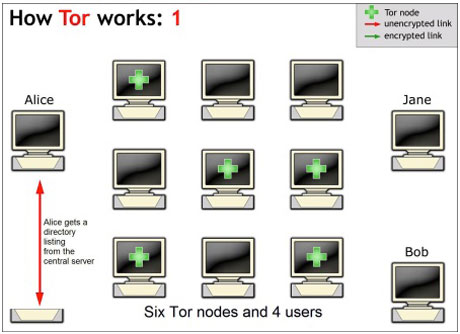
Alices Tor-Client erfragt bei einem Tor-Server ein Directory-Listing mit bekannten anderen Computern, die sich auf freiwilliger Basis als Node im Tor-Netzwerk zur Verfügung stellen. Zu einem dieser Noldes stellt Alice nun die Verbindung her und gibt das gewünschte Ziel der Verbindung (Jane) an. Dieser Node verbindet sich zu einem weiteren und dieser zu einem dritten. Der dritte Node erst verbindet sich tatsächlich mit Jane.
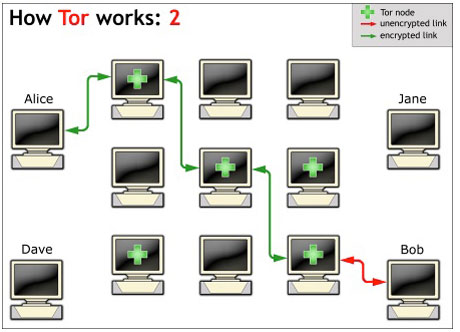
Alle Verbindungen von Alice bis zum letzten Node sind verschlüsselt. Nur der letzte Node kommuniziert ggf. über das unverschlüsselte HTTP mit dem Bob-Webserver.
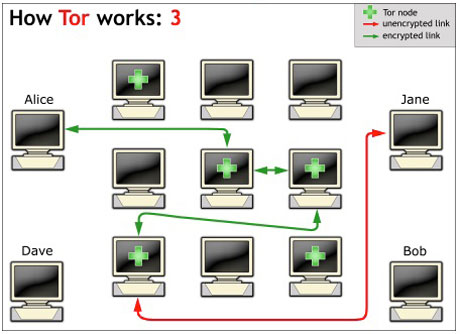
Werden die Leitungen belauscht, ist zumindest eines klar: Der Betreiber des letzten Nodes ist nicht derjenige, der die Verbindung hergestellt hat, um den Content zu empfangen.
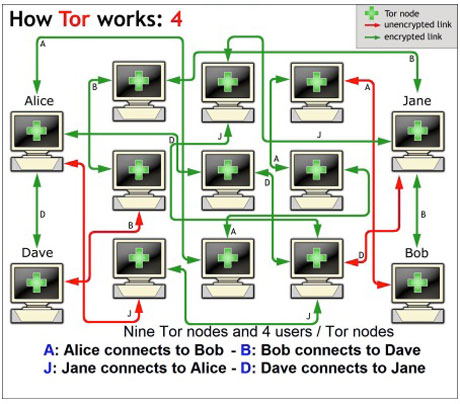
Tatsächlich müssten eine Menge »Spione« unter die Tor-Nodes geschleust werden, um den Absender eines Verbindungswunsches identifizieren zu können. Unmöglich ist das nicht, aber bislang hinreichend schwierig. Deaktiviert man im eignen Browser Cookies und Javascript, kann man sich anonym fühlen. Will man den eigenen Rechner frei von Spuren halten, sollte man Tails verwenden – ein auf DVD oder USB-Stick installierbares Linux mit Tor und zugehörigem Browser.
Die Anonymisierung ist jedoch nur Teil der Tor-Infrastruktur. Das Netzwerk bietet darüber hinaus einen wie oben beschriebenen alternativen Namensdienst, der nicht auf DNS basiert, Namensauflösungen für die so genannten Onion-Domains. Deren Namen sind kryptisch und enden auf die Toplevel-Domain .onion (Zwiebel). Surft man auf eine solche Site, hat man es mit einem Betreiber zu tun, der nur anonymone Besucher haben möchte und darüber hinaus sicher nicht will, dass das eigene Angebot offiziell bekannt wird.
Suchmaschinen existieren auch im Innern dieser Zwiebel. Meist sind es jedoch eher manuell gepflegte Listings für bestimmte Interessentengruppen. Und auch diese muss man erst einmal finden. Ein guter Ausgangspunkt für den Neugierigen ist das Hidden Wiki.
Silk Road & Co.
 In den Onion-Untiefen des »Deep Web« gibt es dann nichts mehr, was es nicht gäbe. Das meiste davon illegal, sieht man einmal von den Wikileaks-Briefkästen ab, und selbst die … Das braucht man wohl nicht weiter zu kommentieren.
In den Onion-Untiefen des »Deep Web« gibt es dann nichts mehr, was es nicht gäbe. Das meiste davon illegal, sieht man einmal von den Wikileaks-Briefkästen ab, und selbst die … Das braucht man wohl nicht weiter zu kommentieren.
Das vielleicht berühmteste Angebot in den Untiefen der Zwiebel ist Silk Road, der anonyme Schwarzmarkt des »Deep Web«, wo man für Bitcoins Drogen, Waffen und Falschgeld und sonstnochwas kaufen könnte, wenn man denn wollte. Man möge mir nachsehen, dass ich die Onion-URLs hier nicht einbinde. Wer sich selbst zutraut, sich in diesen Web-Untiefen unbeschadet umsehen zu können, wird auch die Software einrichten und die Angebote finden. Wer es nicht schafft, bleibt auch besser zu Hause. Dass sich in diesem Anonymous-Dorado Typen herumtreiben, die man eher nicht kennenlernen möchte, kann man sich denken.
Die schiere Menge an fragwürdigen Inhalten und Angeboten im »Deep Web« sollte nicht darüber hinwegtäuschen, dass viele der Aktivisten der Szene keineswegs einem kriminellen Drang folgen, sondern vom Wunsch getrieben sind, im »Deep Web« frei sein zu dürfen: unbelauscht, anonym, ohne dass es dafür einen anderen Grund gäbe als die Sache selbst. Diese Position hat vieles für sich, wenn sie auch die Cyberkriminalität bewusst in Kauf nimmt.
Diverse weiterführende — und die Augen öffnende — Informationen findet man übrigens im Weblog von gAtO. »Wohl bekomm’s« wäre bei der Empfehlung dieser Lektüre allerdings – nun ja: irreführend.






Am 1. Oktober 2012 um 15:05 Uhr
Herzlichen Dank für die Erinnerung bzw. den Hinweis, ich hatte irgendwann einmal davon gehört, mich aber nicht näher damit beschäftgt!
Am 17. Mai 2013 um 23:25 Uhr
Guter artikel, sehr gut erklärt. Auch dass die, die nicht ins Deep web kommen, weil sie zu Jung/blöd/whatever sind, auch keine Anleitung finden.(jedenfalls hier nicht)
Was noch zu erwähnen ist: Silk Road bietet Freiheiten, die man sonst niergends finden kann. Auch leute, die was gegen die „geleugnete Demokratie“ haben, kommen dort zu wort.